Día de la Lengua Rusa: estudian cambio de frecuencia de palabras en la literatura
Por Tania María Robles Hernández
México, DF. 6 de junio de 2015 (Agencia Informativa Conacyt).- La Organización de las Naciones Unidas (ONU), específicamente el Departamento de Información Pública, declaró al 6 de junio como el Día de la Lengua Rusa, iniciativa para celebrar el plurilingüismo y multiculturalismo internacional. En ese sentido, se celebran seis idiomas oficiales de dicha organización: ruso, francés, chino, inglés, español y árabe.
 La lengua rusa abarca más de un cuarto de la literatura científica, además de ser el idioma eslavo más usado actualmente, de acuerdo con la Embajada de la Federación de Rusia en México.
La lengua rusa abarca más de un cuarto de la literatura científica, además de ser el idioma eslavo más usado actualmente, de acuerdo con la Embajada de la Federación de Rusia en México.
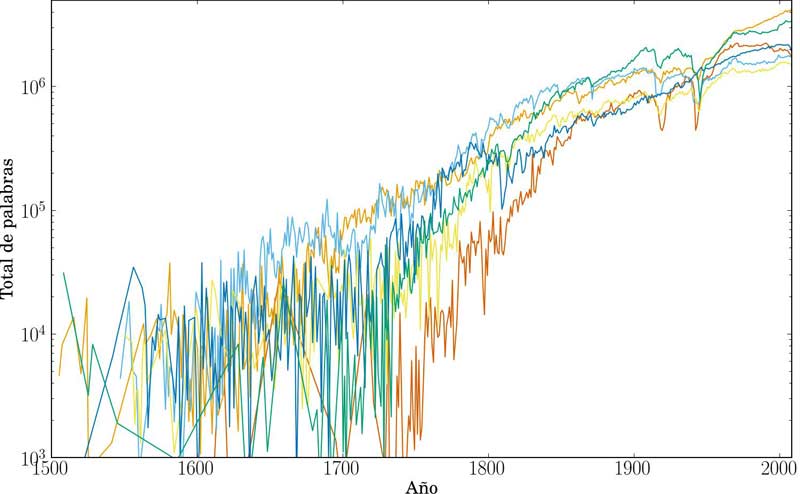
 En nuestro país hay estudios científicos en torno a este y otro idiomas. Como por ejemplo el proyecto realizado por un grupo de Investigadores del Instituto de Física (IF), del Instituto de Investigaciones en Matemáticas Aplicadas y en Sistemas (IIMAS) y de la Facultad de Ciencias de la Universidad Nacional Autónoma de México (UNAM) que estudió, mediante herramientas computacionales y estadísticas, la frecuencia de aparición de palabras en la literatura registrada desde 1800 hasta 2009, que ofrecen las bases de datos de Google Books.
En nuestro país hay estudios científicos en torno a este y otro idiomas. Como por ejemplo el proyecto realizado por un grupo de Investigadores del Instituto de Física (IF), del Instituto de Investigaciones en Matemáticas Aplicadas y en Sistemas (IIMAS) y de la Facultad de Ciencias de la Universidad Nacional Autónoma de México (UNAM) que estudió, mediante herramientas computacionales y estadísticas, la frecuencia de aparición de palabras en la literatura registrada desde 1800 hasta 2009, que ofrecen las bases de datos de Google Books.
La investigación fue publicada en Plos One bajo el título “Rank Diversity of Languages: Generic Behavior in Computational Linguistics”Rank Diversity of Languages: Generic Behavior in Computational Linguistics”.
 Los doctores Germinal Cocho Gil, Jorge Flores Valdés, Carlos Pineda Zorrilla y Carlos Gershenson García, junto con el estudiante Sergio Sánchez Chávez, trabajaron con más de 640 mil millones de palabras de seis idiomas diferentes: inglés, español, francés, alemán, italiano y ruso. “La cantidad de datos que tuvimos que procesar es gigantesca, al final no es tan fácil, uno tiene que estar mucho tiempo programando y procesando datos”, comentó Pineda Zorrilla.
Los doctores Germinal Cocho Gil, Jorge Flores Valdés, Carlos Pineda Zorrilla y Carlos Gershenson García, junto con el estudiante Sergio Sánchez Chávez, trabajaron con más de 640 mil millones de palabras de seis idiomas diferentes: inglés, español, francés, alemán, italiano y ruso. “La cantidad de datos que tuvimos que procesar es gigantesca, al final no es tan fácil, uno tiene que estar mucho tiempo programando y procesando datos”, comentó Pineda Zorrilla.
Estos idiomas de la familia indoeuropea representan el 17 por ciento de hablantes nativos a nivel mundial y fueron elegidos debido a que tienen mayor número de datos; así lo afirma la investigación de los científicos ya mencionados.
Dicho documento de estudio agrega que los datos o palabras fueron depurados en cada lengua haciendo a un lado los vocablos que no pertenecían al mismo idioma o con caracteres no registrados en el alfabeto del mismo. Tampoco fueron tomadas en cuenta como diferentes palabras la lematización en los conjuntos estudiados. La cantidad mínima de apariciones para que las palabras fueran tomadas en cuenta fue de 40.
Para facilitar el estudio, los investigadores clasificaron los vocablos de acuerdo a dos tipos: palabras de contenido y palabras funcionales. Las primeras representan la expresión de ideas, mientras que las segundas son auxiliares en la emisión de mensajes, tales como artículos, pronombres, conjunciones, verbos auxiliares, interjecciones, partículas y preposiciones.
La frecuencia otorga el rango
Una vez que los datos o palabras fueron depurados y ordenados para llevar a cabo la investigación, se nombró una característica que definiría la posición que ocupan las palabras de acuerdo a la frecuencia de aparición en todos los libros escaneados en cierto año; se le llamó rango. “Si cuentas todas las palabras que aparecen en un año, el primer lugar es el que aparece más: es rango uno. El rango dos es el que apareció en segundo lugar”, explicaron Gershenson García y Sánchez Chávez.
Agregaron que un mayor numero de repetición resulta en un menor rango de la palabra –es decir, primeros lugares– y, de manera inversa, a menor repetición entonces mayor rango o últimos lugares en la clasificación.
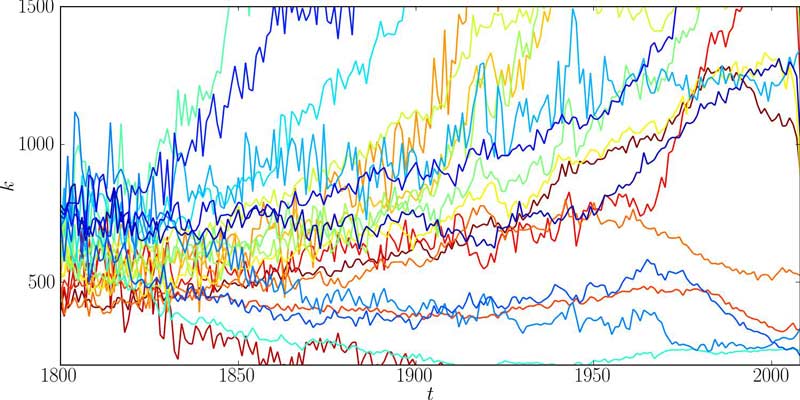
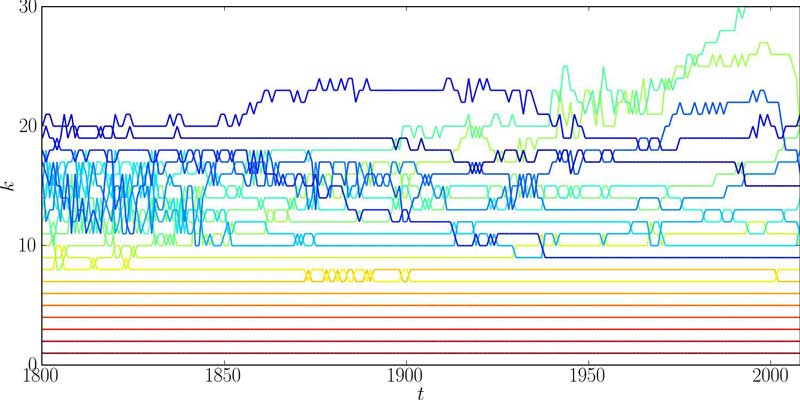
Los investigadores del IF, IIMAS y Facultad de Ciencias observaron que la trayectoria –es decir, el rango que ocupa año con año determinada palabra– fuera menos cambiante cuando se trata de palabras con menor rango, al contrario de palabras con mayor rango, en las que su trayectoria es mayor y aleatoria. “Las palabras que más se utilizan cambian menos su nivel de uso en el tiempo, al contrario de las que menos se usan”, aseveró Gershenson García, quien es jefe del Departamento de Ciencias de la Computación del IIMAS.
Otro factor importante que puede o no alterar el rango es el contexto histórico y cultural de la época; por ejemplo, en el caso específico de la lengua rusa, la historia militar impactó profundamente el aumento del número de palabras en el periodo comprendido entre la Segunda Guerra Mundial y la caída de la Unión Soviética, así como una disminución durante las dos guerras mundiales. Al respecto, el investigador agregó: “Durante las guerras, esas cuestiones históricas se vieron reflejadas en todos los lenguajes”.
Abundó que –en relación también a la lengua rusa– en 1917, tras la revolución rusa, hubo un cambio en el idioma, lo que a su vez hizo que muchas palabras se modificaran.
Aleatoriedad
Los científicos buscaron una medida que reuniera en común a los seis idiomas y que mediante la aplicación de herramientas estadísticas pudiera predecir o modelar los cambios de rango de las palabras a través del tiempo.
Para la creación del modelo se definió como variable la diferencia de rango entre un año y el siguiente; se le llamó diferencia de paso. En el caso de las palabras con los primeros diez rangos, la diferencia de paso fue igual a cero o a uno. En este modelo no fue tomado en cuenta el significado de las palabras o contexto histórico, simplemente su rango, detalló Gershenson García.
Una forma de ordenar la distribución de las palabras en la variabilidad de su diferencia de rango fue nombrar tres grupos con cualidades específicas: uno denominado como cabeza, en el que la diferencia de rango que presentan las palabras es muy bajo y comprenden desde el rango uno hasta el rango 15; otro grupo llamado cuerpo, donde las palabras cambian de rango entre ellas y son consideradas desde el rango 16 al 2 mil 447, con el 95 por ciento de los elementos evaluados; y finalmente el grupo cola, que contiene palabras que van desde el rango 2 mil 448 y que realizan saltos de rango muy grandes.
Modelo estadístico
El modelo construido por los científicos fue un caminante aleatorio invariante de escala y gaussiano, lo que significa que en él “las palabras darán brincos en su uso de forma aleatoria”, explicó Pineda Zorrilla, quien es doctor en Ciencias.
Los resultados otorgaron la información para dar cuenta de que los cambios o la diferencia de rango son inversamente proporcionales al rango de la palabra. “Entonces, si una palabra es usa mucho, sus saltos serán pequeños. Si se usa muy poco, sus saltos serán grandes. Esto se mete a una variable gaussiana para darle un poco de aleatoriedad, se deja correr para varios años y se captan esos saltos aleatorios de las palabras”, añadió el científico.
Predicciones estadísticas
Los investigadores establecieron que mientras menos común sea una palabra, mayor es la probabilidad de que desaparezca. “Ese cálculo es muy fácil de hacer para nosotros, podemos predecir estadísticamente cuánto tiempo vivirán las palabras, si serán cien años o mil años. Puedes correr el modelo el tiempo que quieras”, abundó.
Aunque eso da una predicción promedio, una estadística. “Eso no puede decir mucho porque siempre se tendrán excepciones en la práctica; se puede dar el promedio de vida de una palabra de cierto rango, aunque eso no quiere decir que esa palabra no pueda bajar de rango y volverse más popular”, dijo Gershenson García al referirse a algún cambio en el contexto histórico o cultural que se pueda dar de un momento a otro y alterar la frecuencia de la palabra en cuestión.
Por ejemplo, explicó que en 1911, en México el vocablo “a” se escribía con tilde, pero la Real Academia de la Lengua (RAE) la eliminó; “á” era una palabra de muy bajo rango y al cambiarla desapareció, entrando de la nada “a” sin tilde.
Otro ejemplo es la representación de la vida media de un vocablo que el modelo de los investigadores puede predecir con la palabra “gato”, la cual aseguran podría sobrevivir 500 años. “Sería muy raro que en cinco años la palabra desapareciera, pero también sería raro que en 2 mil años todavía existiera”, dijo al respecto Pineda Zorrilla.
Esta escala de vida media no significa que cuando se cumpla exactamente ese tiempo entonces sucederá. “El modelo solamente te da una sensación de cuánto tiempo puede vivir una palabra”, concluyó el especialista.