Politécnicos desarrollan traductor básico español-mixteco
Por Armando Bonilla
Ciudad de México. 20 de junio de 2018 (Agencia Informativa Conacyt).- Un algoritmo que permite traducir del español al mixteco fue desarrollado por alumnos de la Escuela Superior de Ingeniería Mecánica y Eléctrica (ESIME, Culhuacán) del Instituto Politécnico Nacional (IPN).

Ernesto Hernández Bernal y Leo Zuriel Hernández Castillo, estudiantes de octavo semestre de la carrera de ingeniería en computación, bajo la dirección de la doctora Iovanna Alejandra Rodríguez Moreno y el doctor Jorge Fernando Veloz Ortiz, concretaron esta versión funcional del traductor básico.
Previo a la programación del algoritmo, los jóvenes politécnicos que llevaron a cabo este proyecto como parte de sus esfuerzos de titulación, realizaron una investigación documental y de campo en torno al mixteco que les permitió identificar trece variantes diferentes.
|
Las tonalidades mixtecas El mixteco, por su carácter tonal, cuenta con alrededor de 13 variantes; se estima que es hablado en dos mil 463 localidades del país —principalmente en Oaxaca, Guerrero y Puebla— y que en cada una de ellas, cinco por ciento de su población habla alguna de sus variantes. Fuente: XII Censo General de Población y Vivienda del Instituto Nacional de Estadística y Geografía (Inegi). |
A partir de esa información, eligieron una de ellas y entablaron colaboración con una comunidad en Oaxaca —Chalcatongo— para que sus habitantes los ayudaran a generar una base de datos lo suficientemente robusta de palabras en mixteco, que posteriormente integraron a su algoritmo, para desarrollar así una primera versión del traductor.
Ya probado el algoritmo, en una siguiente etapa desarrollaron la interfaz de una aplicación (app) para Android que en el futuro les permitirá poner su traductor a disposición de todas aquellas personas que cuenten con un teléfono inteligente; no obstante, aún se encuentran en la fase de perfeccionamiento de la app.
En entrevista para la Agencia Informativa Conacyt, la doctora Iovanna Alejandra Rodríguez Moreno, profesora investigadora de la ESIME Culhuacán, explicó que el proyecto surge como parte de los esfuerzos de la ESIME por orientar la formación de los alumnos a la creación de soluciones para los problemas de la sociedad.
“Se trata de proyectos que nos toman tres semestres y esa situación supone un reto, pues hay que trabajar en conjunto con otros profesores para garantizar su seguimiento y desarrollo hasta una etapa de prototipado (…) Iniciamos con la elaboración de un protocolo de investigación, después los alumnos trabajan en la investigación de líneas paralelas y asignaturas de especialidad que apoyen la elaboración de su proyecto y finalmente lo llevan a cabo”.
Las entrañas del traductor
“Nuestro algoritmo de árbol sintáctico descendente (ASD) recibe como entrada una palabra en español y al pedirle que la traduzca, la somete a una serie de análisis que van desde cómo está escrita —define si se escribió correctamente— hasta su significado para después identificar su equivalente en mixteco”, dijo Ernesto Hernández Bernal.
Por su parte, Leo Zuriel Hernández Castillo explicó que el algoritmo está compuesto de tres bloques principales: uno de análisis, otro de síntesis y otro integrado por la base de datos del mixteco.
“La base de datos la realizamos en un sistema de gestión relacional llamado SQLite, ideal para el manejo de bases de datos, con una pequeña biblioteca en aplicaciones de dispositivos móviles porque optimiza el consumo de recursos y además cuenta con una gran capacidad”, precisó Hernández Bernal.
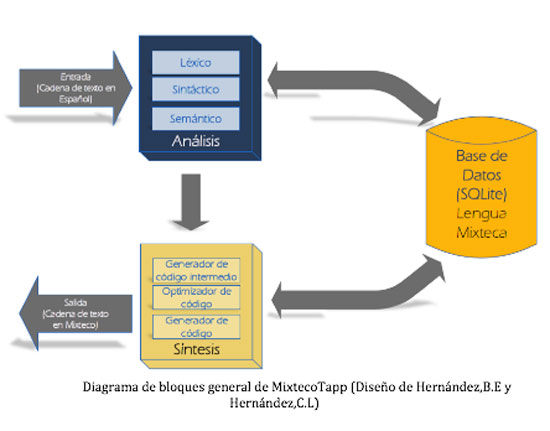
Mientras tanto, Hernández Castillo dijo que el bloque de análisis está compuesto por otras tres fases —análisis léxico, sintáctico y semántico—. “Durante el primer análisis, un rastreador reconoce los componentes léxicos para generar lexemas y tokens, es decir, palabras atómicas o simbólicas que son utilizadas en la siguiente fase —análisis sintáctico—, donde nuestro algoritmo realiza un análisis descendente”.
Durante ese proceso, el algoritmo toma los lexemas y tokens para hacer un árbol de derivación derecha, que lee las cadenas generadas de izquierda a derecha, partiendo de la gramática de contexto libre que establece los pares lexema-token mediante una organización de match o concordancia.
La etapa final es el análisis semántico, donde los componentes que arroja el árbol gramatical hacen una correlación que permite correspondencias a lenguaje de bajo nivel. El bloque de síntesis también está dividido en tres fases: generación de códigos intermedios, generación de códigos y la salida del código equivalente.
“Básicamente realizamos un análisis muy completo de la palabra que se introduce para que la traducción que arroje nuestro algoritmo sea la correcta”, añadió Hernández Castillo, quien precisó que aún trabajarán más en su algoritmo antes de poner a disposición del público la aplicación, pues buscarán que no solo traduzca palabras aisladas sino que logre traducir frases completas y que lo haga en ambos sentidos, es decir, de español a mixteco y de mixteco a español.
 Descargar fotografías.
Descargar fotografías.

Esta obra cuyo autor es Agencia Informativa Conacyt está bajo una licencia de Reconocimiento 4.0 Internacional de Creative Commons.
